May 19, 2026 · build log
Signals: an early-warning system for internet momentum
I built an open-source tool that watches behavior changes, not mention counts, across Reddit, Hacker News, GitHub, Polymarket and a few other independent sources. Every claim is backed by a clickable packet of evidence. Below is a tour of what it does, then how I use it with a coding agent like Claude Code or Codex.
Repo: github.com/alejandroclvi/Signals · MIT.
The problem
By the time TechCrunch covers an AI shift, three founders already pivoted. By the time a Reddit thread goes viral, the moment to enter the conversation is gone.
Most “social listening” tools count mentions and slap a sentiment score on top. That tells you what is loud. It doesn't tell you what is changing — and changing is what predicts where things are going.
Signals does three things differently:
- Behavior changes, not mentions. People starting to ask for the same thing. People switching tools. Companies hiring for a new role. A complaint spreading across communities. A repo quietly getting starred by the right kind of user.
- Evidence-first. Every claim dereferences to a packet — a Reddit post, a comment, a GitHub PR, a market price move — with the source URL one click away.
- Independence over volume. One Reddit thread plus a rising search trend plus a GitHub PR beats ten upvoted Reddit posts in related subs.
The radar
The home screen is a radar. KPIs across the top — emerging signals, high-confidence ones, communities being watched, evidence saved. A bubble chart plots every signal by relevance × momentum. The right rail is an inbox you can rank, filter, and triage.
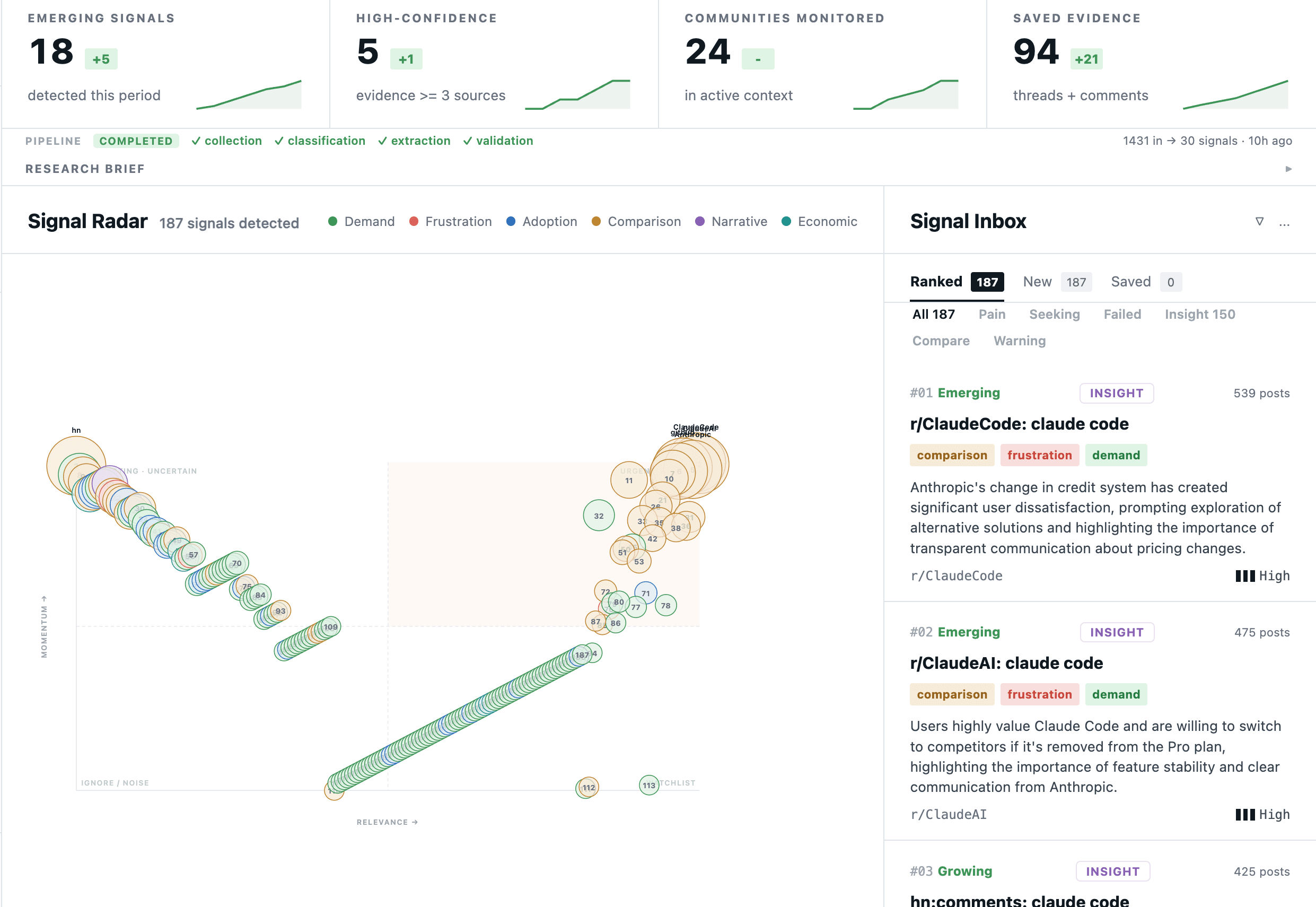
Each bubble is a signal — a claim that something is changing. Bigger means more evidence behind it. Color tells you what kind of behavior change. The list on the right is the same data ranked, so you can work top-down instead of by visual hunting.
Seven independent ways to see
Behind every signal sits a mesh of producers, each one a different angle on the same topic. The premise: if seven different kinds of source all hint at the same change, the change is real. If only one does, you have a rumor.
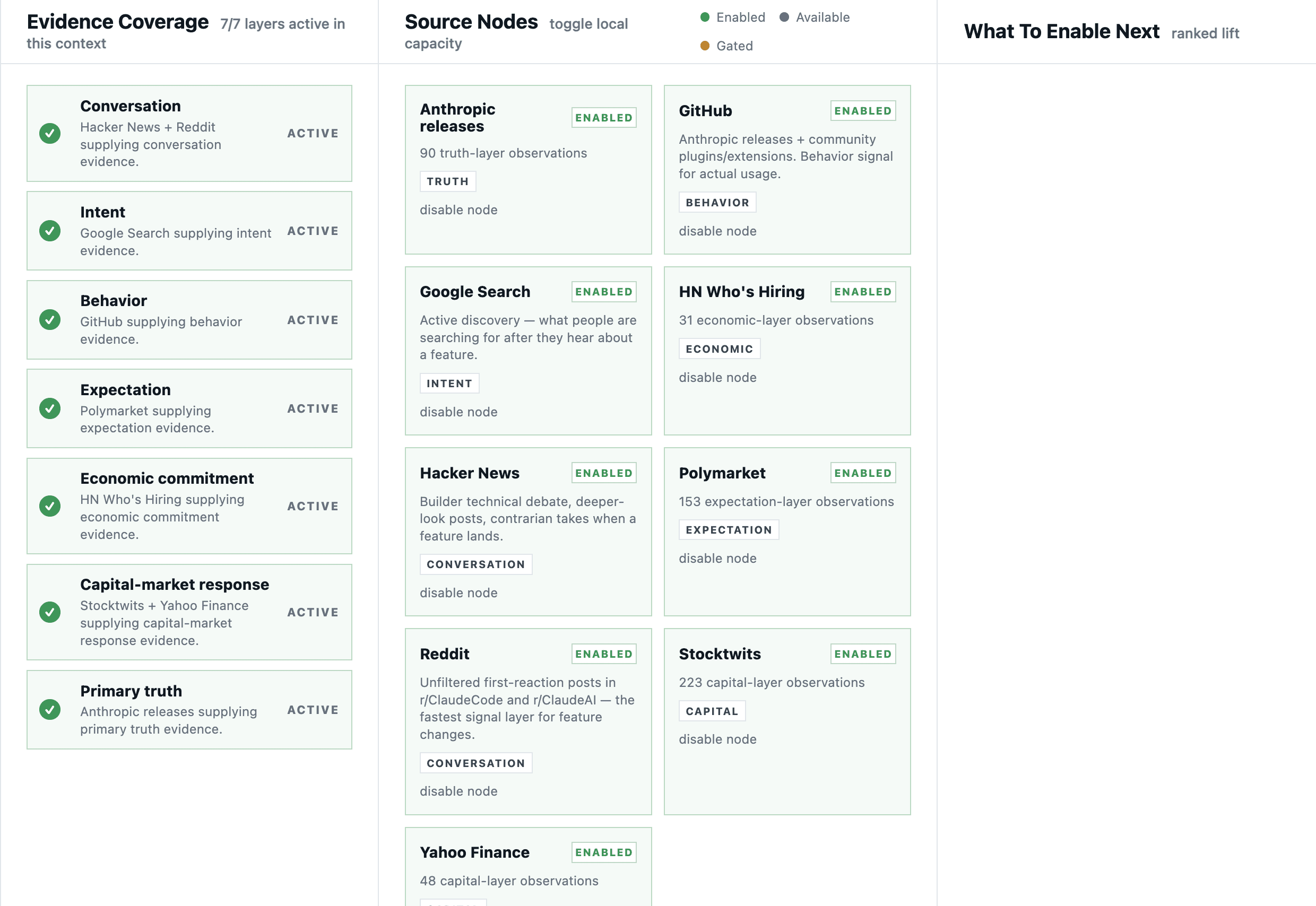
Adding a new source is a matter of writing a small producer that returns a normalized evidence packet. The registry handles the rest — scheduling, dedupe, lifecycle tracking, scoring contributions. The point is that missing coverage is itself a finding: if a signal has Conversation but no Behavior, that's a clue about whether anyone is actually building anything in response.
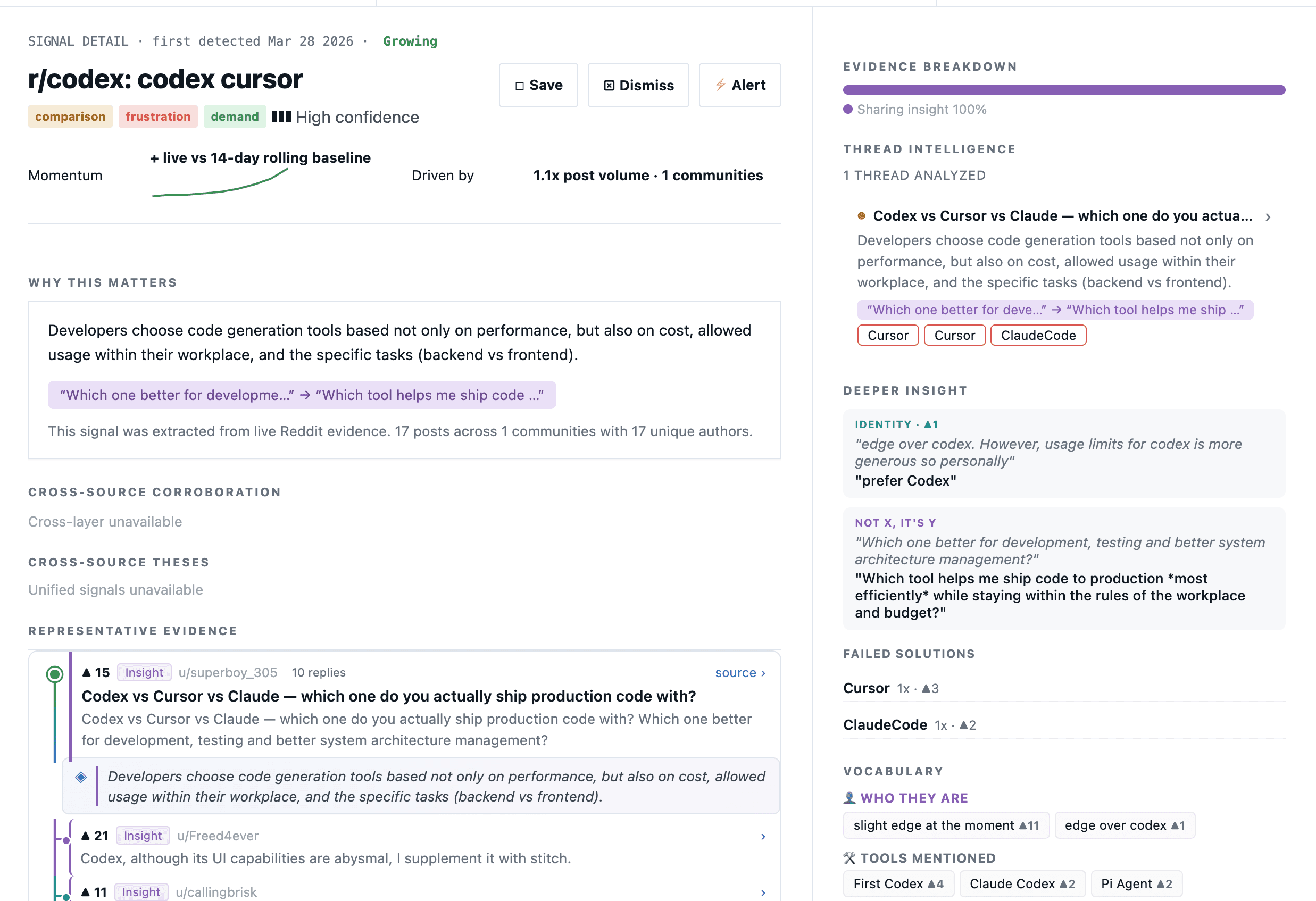
One signal, end to end
Click into a signal and you get the whole chain. Lifecycle stage. Momentum. The communities driving it. A “why this matters” written from the evidence. Threads ranked by score and reconstructed so you can read the parent post and the comments it sparked.
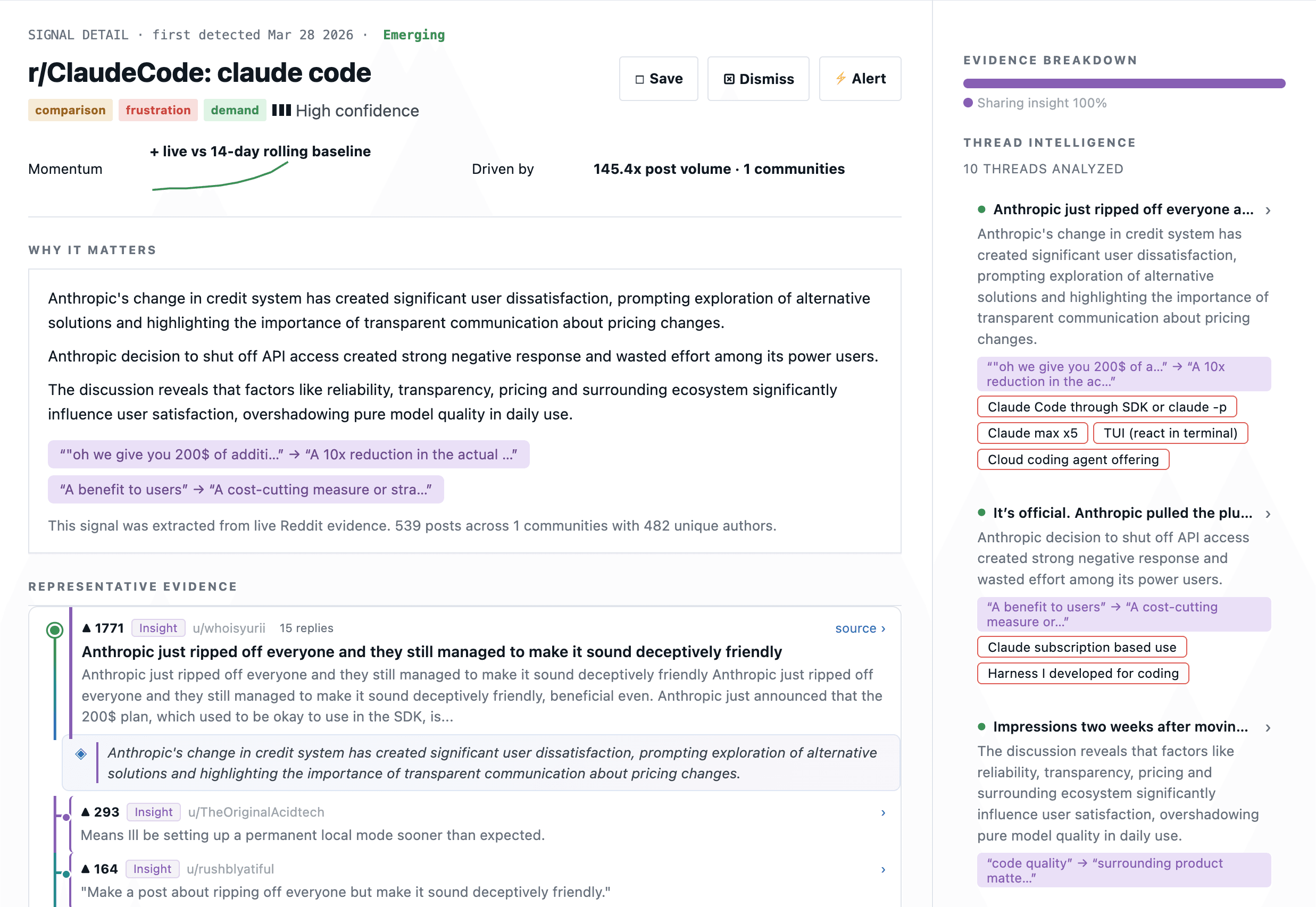
Notice the small tags under each comment — insight, pain, comparing. Every piece of evidence is classified for where the person is in their journey (experiencing a problem, trying things that failed, sharing what works, warning others, etc). That's how you separate “people are complaining” from “people are switching tools because of the complaint.”
Cross-source corroboration (and what's missing)
This is the load-bearing claim of the whole system. A signal isn't real until independent sources point at the same thing. So the detail view shows, layer by layer, what you have and — equally important — what you don't.
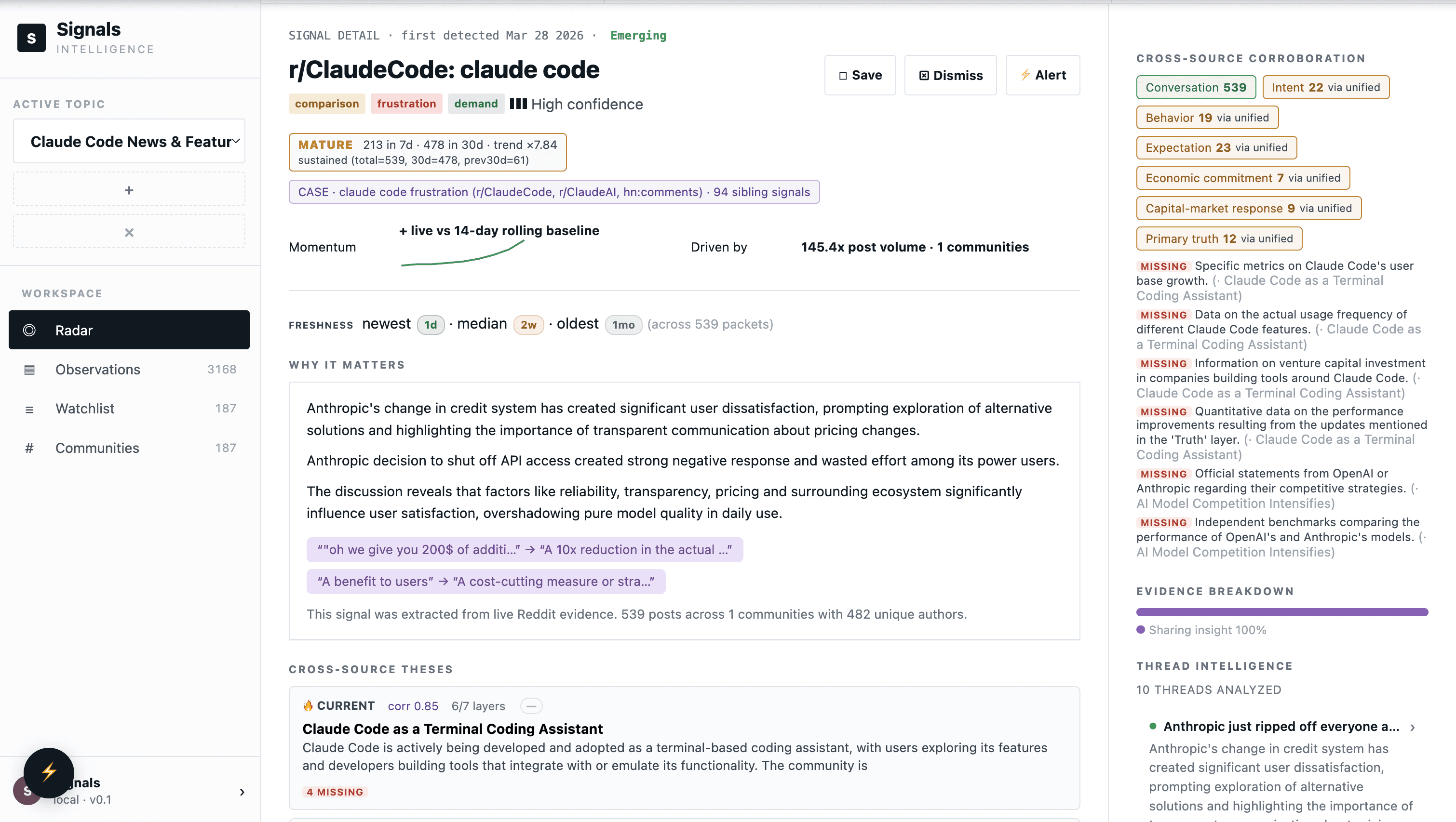
Most dashboards hide gaps. This one pins them to the surface, because missing evidence is the cheapest, most honest signal you have. If a claim ought to be backed by usage stats and there are none, that's a directive: go look.
Drill all the way to the source
Every packet links to its original URL — the Reddit thread, the Polymarket market page, the GitHub PR. Clicking a piece of evidence opens a panel that shows where it came from, which signal cites it, and a one-click jump to the live source. There is no “trust me” layer.
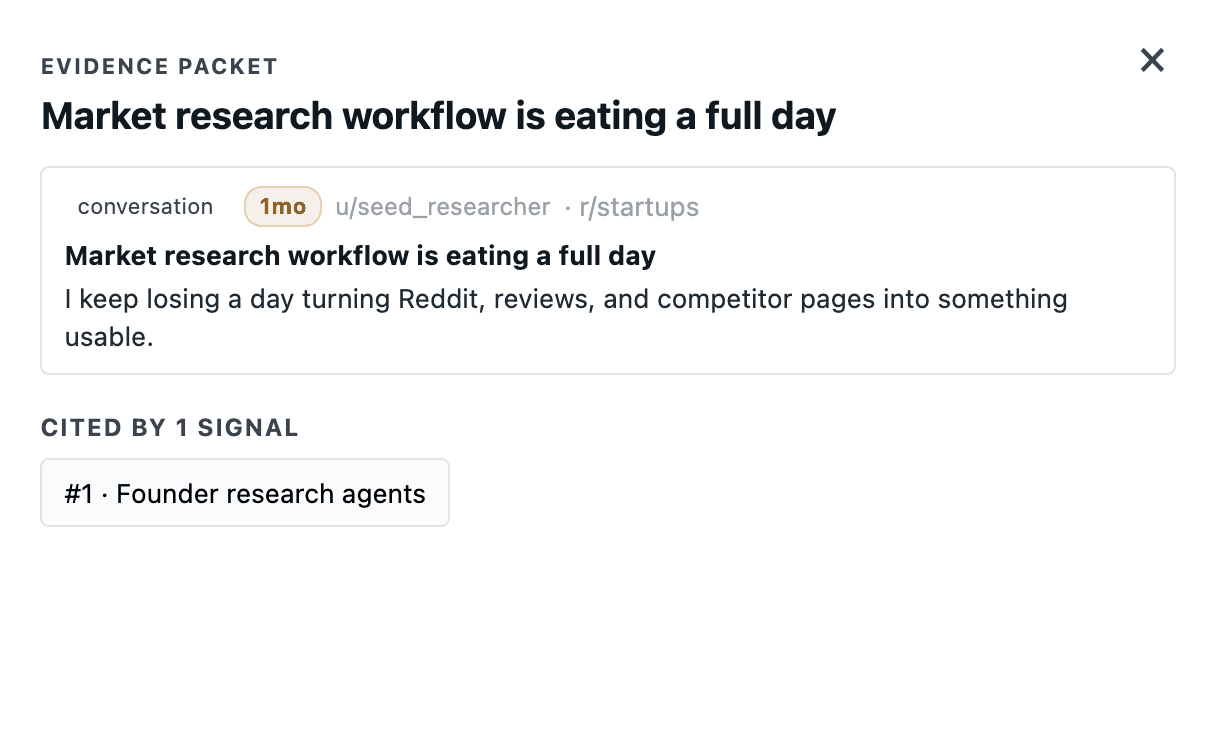
Comparison signals, not just complaint signals
One of the more useful classes of behavior change is comparison — people actively weighing two tools against each other. Those threads are where switching decisions get made, and the language people use is gold.
Driving it with Claude Code or Codex
Signals is built to be operated by a coding agent, not babysat. The repo ships with two README files written for two different audiences: HUMAN_README.md for the operator, AGENT_README.md for whatever agent you point at it. Drop the agent into the repo, tell it to read both, and it can do real work in minutes.
Setup once
git clone https://github.com/alejandroclvi/Signals cd signals pnpm setup # install, build DB, seed sample data cp .env.example .env # paste your OPENROUTER_API_KEY pnpm doctor # green-checks everything is wired pnpm dev # dashboard on http://localhost:3000
Common agent loops
- Add a new source. “Read
src/pipeline/producers/and add a producer for Product Hunt that matches the existing shape.” The agent picks up the contract from a neighbour, wires it intoregistry.mjs, and lands the change. - Run an adaptive research loop.
pnpm research <context-id>assesses what coverage gaps the context has, generates targeted queries using vocabulary from existing evidence, discovers new threads, classifies them with an LLM micro-classifier, then re-assesses. The agent doesn't need to write any queries — the system writes them. - Reseason a signal. Click Analyze in the UI, or hit
POST /api/signals/:id/analyze. The agent runs thread intelligence on that signal's threads (LLM-reconstructed full conversations through Gemini Flash via OpenRouter), reconciles with the regex pass, and refreshes scores. - Generate content from signals.
pnpm flow run linkedin-from-poststakes the highest-quality evidence and drafts post copy.pnpm flow run weekly-publishwraps up the week and produces drafts you can actually paste into LinkedIn or Instagram. Every line in the draft has a citation token ([ev:<id>]) so you can verify the claim before publishing. - Push updates back into the dashboard from the agent. The UI listens on a Server-Sent Events channel. From the terminal:
curl -X POST localhost:3000/api/toast \ -d '{"message":"Analyzing 14 threads...","type":"info"}' curl -X POST localhost:3000/api/report \ -d '{"title":"Research Brief","body":"## Thesis ...","format":"markdown"}'This is how a long-running agent narrates itself to the operator without flooding the terminal.
What makes it agent-friendly
- One contract per file. Every producer, every flow step is a small module with a single exported function. The agent doesn't have to hold the whole codebase in its head to make a change.
- Transparent scoring. No black-box trend score. Every number decomposes into named components. The agent can explain why a signal is ranked where it is — and so can you.
- A 44-check smoke test.
pnpm test:smokevalidates DB invariants — every context has queries, every evidence packet has a source kind, no signals without evidence, no duplicates. The agent is allowed to land changes only if smoke stays green. That single gate has prevented more bad merges than any test suite I've written the conventional way.
Why I open-sourced it
Two reasons. First, I want this kind of evidence-first early-warning to be the default for anyone building in fast-moving categories — founders, analysts, product leaders — not a feature gated behind a $500/mo SaaS. Second, the most useful version of this system is the one you customize for your own topic, your own sources, and your own way of thinking. That's only practical if the code is yours to edit.
If you build something interesting on top of it, I'd love to see it.